


基于扩散变换器的人工智能中台模型构建与优化
李延林1 刘 奥2 赵 城3
(1.泰国正大管理学院,曼谷,10250;2.英国格拉斯哥大学,格拉斯哥,G128QQ;3.深圳市金橙果科技有限公司,深圳,518057 )
摘要:
本文提出了一种新颖的扩散变换器模型,命名为紫杉中台模型,旨在增强人工智能应用体在文本应答方面的性能。紫杉中台模型结合了自然语言处理中的Transformer模型和物理学中的扩散过程,通过连续、渐进的方式将原始语句转变为目标语句。本文从紫杉中台模型的模型架构、工作机制、应用场景等方面进行了详细介绍,并通过实验验证了其在语境分析、隐性需求挖掘、应答方案选择、输出语言组织四个维度上的优秀性能。此外,紫杉中台模型作为中台模型,能够有效降低输送到大模型的信息熵,节省算力,增加可控相变,提高大模型的进化效率和应用生成质量。本文认为,紫杉中台模型将为文本类人工智能的进化提供有价值的实践,并有望在未来扩展到图片生成和视频生成的大模型中。
关键词:人工智能;中台模型;扩散变换器;文本应答
一、引言
随着人工智能技术的不断发展,生成式文本类应用在各个领域得到了广泛应用。传统的文本应答模型在处理复杂、多变的文本信息时仍存在诸多挑战,如语境理解不准确、隐性需求挖掘不足、应答方案选择不合理、输出语言组织不流畅等问题。为了解决这些问题,本文提出了一种新颖的扩散变换器模型——紫杉中台模型,旨在通过引入扩散过程的性质,将原始语句逐步转变为目标语句,形成连续的、渐进式的语言模型,从而提高文本应答的质量和效率。
二、研究背景
2.1人工智能发展浪潮下文本应答模型的崛起
人工智能技术的蓬勃发展使得文本应答模型不断更新迭代,随着深度学习算法的不断演进,从早期的简单神经网络架构逐步发展到如今的Transformer架构及其变体,其计算能力得到了显著提升,从而使得文本应答模型在智能客服、智能写作、信息检索辅助等诸多领域展现出广阔的应用前景。如在智能客服领域,企业期望通过高效准确的文本应答系统迅速响应客户咨询,提升客户满意度与服务效率,减少人力成本投入;在智能写作方面,可辅助创作者快速生成初稿、优化语句结构与风格,加速内容创作流程;在信息检索辅助则帮助用户精准定位所需信息,提升信息获取效率,改变知识传播与利用模式。
并且如今各行业数字化转型加速,对智能化文本处理需求日益增长,医疗行业需借助文本应答模型精准解读病历、辅助诊断决策、提供健康咨询,以应对医疗资源分布不均与人口老龄化带来的挑战;金融领域期望利用模型实现智能投顾、风险预警、信贷审批自动化,优化金融服务流程、提升风险管控能力;教育行业则探索智能辅导、作业批改、个性化学习建议等应用,推动教育公平与个性化教育发展。各个产业需求不断增长,成为文本应答模型技术创新与突破的核心驱动力,推动学界业界不断探索更优模型架构、训练方法与性能优化策略,以契合多样化产业场景需求。
2.2 传统文本应答模型的限制
传统模型大多聚焦词汇与句法表层分析,对语义深度挖掘能力匮乏,因此面对文学作品隐喻、口语俗语隐喻、商务委婉表述等复杂语境,经常因缺乏语义关联拓展与背景知识融合能力而错判语义。在文学经典解读中,难以领悟隐喻意象背后丰富意蕴;在商务谈判中,曲解委婉措辞背后意图,破坏合作契机。通过多轮对话,随着对话的不断推进难以维系语境的一致性,关键实体指代消解混乱、主题漂移失控,如智能客服对话中频繁遗忘前文关键信息,导致服务质量严重下滑,无法为用户提供连贯、精准应答,难以满足复杂交互场景需求。
在日常生活中,用户的需求往往隐匿于情感、行为意图的深层角落,传统模型挖掘技术粗放,情感分析停留在正负情感简单判别,细微情绪色调差异洞察缺失,难以依据情感线索精准定位其需求内核。行为大数据挖掘浅层,浏览轨迹停留时长、页面切换频率模式识别单一,购买历史品牌风格、价格区间偏好动态演变捕捉失效,构建用户画像失真失准。个性化推荐沦为普适推荐,如音乐平台依用户行为推荐曲目风格混杂、电商平台产品推荐未契合用户消费升级趋势,无法满足用户多元、动态个性化诉求,在竞争激烈市场中逐渐渐失竞争力。
2.3 紫杉 中台模型的应运而生
鉴于传统文本应答模型在多个关键维度的显著缺陷,难以有效应对现实场景中复杂多变的文本处理需求,严重制约人工智能在文本交互领域的发展进程。因此,本文创新性地提出 紫杉 中台模型,其融合自然语言处理领域的 Transformer 架构优势与物理学中的扩散过程理论精髓,通过独特设计与优化机制,致力于突破传统模型瓶颈,紫杉 中台模型将为文本类人工智能的进化开辟全新路径,提供极具价值的实践范例,不仅有望重塑文本应答领域格局,更预期在未来拓展至图片生成和视频生成等多模态大模型领域,推动人工智能技术边界持续拓展与性能飞跃,开启智能交互新时代。
三、紫杉中台模型介绍
3.1 扩散变换器的定义
扩散过程是指一个系统从初始状态向稳定状态的演进过程,具有连续性和渐进性。变换器(Transformer)是一种深度学习模型,拥有强大的并行处理能力和长距离依赖捕捉能力。紫杉中台模型结合了两者的优势,通过引入扩散机制,将Transformer模型中的自注意力机制和位置编码等组件进行改进和优化,创造了独特的扩散变换器模型。
3.2 紫杉中台模型架构
紫杉中台模型主要由输入层、编码层、变换层和解码层组成。输入层负责接收原始文本并提取有效信息标记;编码层采用变分自编码器(VAE)将原始文本编码成潜在空间中的特征向量;变换层包含一系列Transformer block,用于离散和重组文本中的知识需求和情感需求;解码层负责将变换后的特征向量解码为目标文本。
3.3 紫杉中台模型优势
紫杉中台模型在文本处理方面优势明显。首先,接入紫杉中台模型的通用大模型在文本应答方面明显提高了流畅性和准确性。其次,有效提高了智能体处理复杂多变的文本信息的能力。此外,紫杉中台模型还引入了高效的变体来减少信息熵,进一步增强了其在文本应答方面的优势。
四、紫杉中台模型工作机制
4.1 扩散变换器的工作原理
扩散变换器的工作原理是通过连续添加高斯噪声来破坏训练数据,然后通过逆转这个加噪过程来学习恢复数据。在训练过程中,逐渐在标的数据中加入纯高斯噪声,并通过学习逆过程来恢复原始标的数据。扩散模型是一种潜变量模型,逐渐向数据添加噪声,以获得近似的后验q(x1:T|x0),其中x1,...,xT是与x0具有相同维度的潜变量。训练的目标是学习逆过程,即训练pθ(xt−1|xt)。通过这种方式,扩散模型能够学习到含噪文本数据的潜在结构和分布特征。为更直观表示,我们用图像代替文本制作示意图。如图1所示。


(图1)
4.2 紫杉中台模型的模型工作过程
紫杉中台模型的工作过程包括输入处理、编码、变换、解码四个步骤。首先,输入层接收原始文本并提取有效信息标记。然后,编码层采用VAE将输入文本编码成潜在空间中的特征向量。接着,变换层利用一系列Transformer block对特征向量进行离散和重组处理,以提取文本中的知识需求和情感需求。最后,解码层将变换后的特征向量解码为目标文本并输出到大模型或用户。如图2所示。

(图2)
4.3 紫杉中台模型的内部世界模型
紫杉中台模型在模型内构建了一个内部世界模型,并通过变分推断和后验分布机制对经过扩散变换器重组后的信息进行学习。这个内部世界模型具备动态迭代的能力,能够持续自我优化,确保与用户的审美偏好保持一致和同步更新。如图3所示。

图3
五、紫杉中台模型应用场景
紫杉的定位是中台模型,他只有嵌入在通用大模型中才可以更好地发挥作用。紫杉中台模型可以有效降低输送到大模型的信息熵,节省算力,增加可控相变,提高大模型的进化效率。
5.1 优化输入输出语句
事物的信息是通过不同层级的随机变量来体现的,这些随机变量各自承载着特定的信息,并共同作用于更高层级随机变量的信息构成。而一个随机变量所传达的外部信息,则由其条件概率分布来决定。在理解语言的复杂性上,人类与机器往往存在逆差:对人类而言简单直观的语言表达,对机器而言却可能异常复杂且难以解析。例如,当用户向一个绘图AI发出指令“三个小孩在放风筝”时,这一简洁描述在机器内部会触发大量不确定的变量考量,如孩子们的年龄、性别比例、放风筝的地点、风筝的类型、他们的情绪状态以及动作是奔跑还是站立等。面对这众多随机变量的组合,机器难以精准定位到用户脑海中构想的具体场景。此时,紫杉中台模型的介入显得尤为关键。得益于其内置的世界模型已学习并掌握了用户的审美偏好,紫杉中台模型能够有效筛选并排除那些不符合用户喜好的干扰因素,进而生成一条更加精确、贴近用户个性化风格的指令,比如:“在中国北方初春的公园草地上,三位身着碎花棉袄的小女孩正欢快地奔跑,手中紧握着一只色彩斑斓的彩虹风筝。”这样的描述不仅丰富了画面细节,也极大地提高了生成图像与用户预期之间的匹配度。
5.2 有效降低大模型幻觉
神经元上先验信念或感觉数据表达的生物异常,会干扰知觉推理过程,进而引发人类的幻觉现象。同样地,大模型也面临着类似的“幻觉”问题,这已成为其应用中的一大障碍。当模型生成的文本与原文不符(缺乏忠实性)或违背事实(缺乏真实性)时,我们即可认为模型出现了幻觉。相关研究已经深刻揭示了这一问题的严重性,并强调了解决大模型幻觉问题的紧迫性和重要性,以确保大模型技术的负责任应用。
我们深入探究发现,大模型幻觉的产生主要归因于以下几个方面:
(1)语料中的偏差与错误导致模型学习了扭曲的外部信息;同时,嵌入构建高维概率语言空间时,精度不足易引发概率向量的混淆。
(2)在重整化提炼语料信息概率分布的过程中,自由能的变化难以保证,使得信息提取成为有损过程;此外,自回归预测仅是对训练语料概率分布的近似逼近,由此构建的内部概率先验存在不精确性。
(3)重整化群在微扰下可能发生对称性破缺,导致内部模型发生相变,而当前缺乏有效的预知与控制方法,增加了内部世界模型结构的不确定性。
(4)宽泛模糊的提示语以及上下文关联的影响,可能使大模型在内部采样时选取存在偏差的子空间进行推理。
(5)在有偏差的子空间中进行推理采样,可能导致采样分布严重偏离最佳采样分布q*;而变分推断获得的采样分布若存在严重偏差,将直接影响对外部后验的预测准确性。
值得注意的是,在先前讨论的4.2和4.3章节中,我们已经详细阐述了紫杉系统能够有效进行语料治理并提高相变的可控性,这两个优势能力恰好针对通用大模型幻觉产生的关键原因,从而显著降低了大模型出现幻觉的概率。
5.3 其他应用场景
除了上述应用场景外,紫杉中台模型还可以应用于其他领域。例如,在智能客服领域,紫杉中台模型能够准确理解用户的意图和需求,并提供更加智能化和拟人化的服务;在信息检索领域,紫杉中台模型能够更准确地匹配用户查询和相关信息等。
六、实验验证
为了深入评估紫杉中台模型的性能,我们开展了一系列严谨的实验探究。这些实验聚焦于四大核心性能指标:语境理解深度、潜在需求发掘能力、应答策略多样性以及语言表达的自然度。实验数据清晰地显示,紫杉中台模型在这四大维度上均有卓越表现。
我们还通过细致的消融实验,逐一验证了紫杉中台模型中各关键组件的有效性。实验结果显示,无论是扩散变换器、内部世界模型,还是变分推断机制,都在提升模型整体性能上发挥了不可或缺的作用。
这些实验不仅验证了紫杉中台模型的强大的性能,也为我们后续的研究和应用提供了坚实的实证基础。我们坚信,紫杉中台模型在自然语言处理领域将展现出更加广阔的应用前景和深远的影响力。
七、结论与展望
本文创新性地提出了一种名为紫杉的人工智能中台模型,该模型融合了自然语言处理领域的Transformer架构与物理学中的扩散过程理论,通过一种连续且渐进的方式,将原始语句精准地转化为目标语句,从而显著提升人工智能在文本处理方面的性能。紫杉中台模型在语境深度分析、隐性需求有效挖掘、应答方案智能选择以及输出语言精准组织等四大核心维度上,均展现出了卓越的性能表现。我们相信,紫杉中台模型将为文本类人工智能技术的持续发展提供宝贵的实践经验。
展望未来,我们将持续致力于紫杉中台模型的性能优化与功能拓展。具体而言,我们将探索融入更多先验知识与规则,以进一步提升模型的输出质量;同时,我们也将积极寻求更为高效的训练方法与算法,以期加速模型的收敛过程并提升其整体性能。此外,我们还将不断拓展紫杉中台模型的应用领域与场景,以全面验证其卓越的泛化能力与实用价值。
参考文献:
Peebles W, Xie S. Scalable diffusion models with transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 4195-4205.
Ji Z, Lee N, Frieske R, et al. Survey of hallucination in natural language generation[J]. ACM Computing Surveys, 2023, 55(12): 1-38.
Abdar M, Pourpanah F, Hussain S, et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges[J]. Information fusion, 2021, 76: 243-297.
Adlakha V, BehnamGhader P, Lu X H, et al. Evaluating correctness and faithfulness of instruction-following models for question answering[J]. arXiv preprint arXiv:2307.16877, 2023.
Toutanova K, Rumshisky A, Zettlemoyer L, et al. Proceedings of the 2021 conference of the north american chapter of the association for computational linguistics: Human language technologies[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.
Cao M, Dong Y, Wu J, et al. Factual error correction for abstractive summarization models[J]. arXiv preprint arXiv:2010.08712, 2020.
Cao S, Wang L. CLIFF: Contrastive learning for improving faithfulness and factuality in abstractive summarization[J]. arXiv preprint arXiv:2109.09209, 2021.
-

中国大科学装置再上新!先进阿秒激光设施正式开工建设
中新网北京1月10日电 (记者 孙自法)由中国科学院承担建设的国家重大科技基础设施——先进阿秒激光设施,1月10日在广东东莞正式开工建设。 这次上新的大科学装置先进阿秒激光设施被形象称为“超高速摄像机”,共布局10条束线和22个应用终端,当天开工建设的6条束线由中国科学院物理研究所负责,另外4条束线将在陕西西安建设,由中国科学院西安光学精密机械研究所负责。先进阿秒激光设施(广东东莞)俯瞰效果图。
2025-01-10
-

针对拖欠工资和“五险一金”情况,国家医保局要求→
中新网1月7日电 据国家医疗保障局网站消息,日前,国家医疗保障局发布《关于进一步加强劳动者医疗保障权益维护工作的通知》。 《通知》提到,近期有群众反映用人单位拖欠职工工资和“五险一金”缴费,影响其医保权益保障。为进一步加强劳动者医保权益维护工作,落实政策、健全机制、改进服务,不断增强广大劳动者医疗保障的获得感、幸福感、安全感,现就相关事项作出通知。 《通知》主要包括以下内容: 大力做好劳
2025-01-08
-
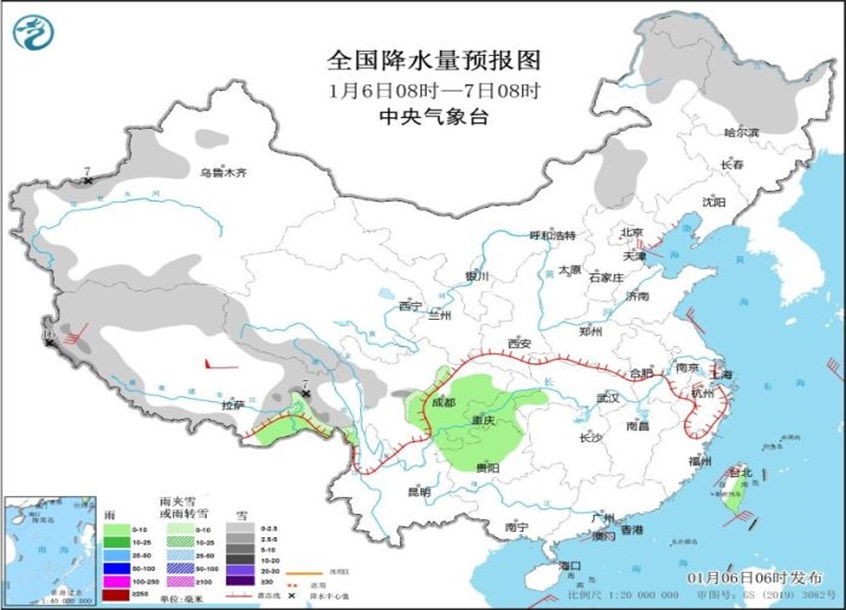
冷空气将影响我国大部地区 西南地区有雨雪天气
中新网1月6日电 据中央气象台网站消息,昨日,全国大部地区降水稀少,内蒙古、吉林等地部分地区出现降雪;内蒙古、山西、京津冀等地风力较大。预计未来三天,冷空气影响我国大部地区,新疆北部、青藏高原有降雪,西南地区东部、江南西部等地部分地区有雨转雪,关注对交通出行等的影响。 冷空气将影响我国大部地区 西南地区和江南西部有雨雪天气 受冷空气影响,6日夜间至9日,西南地区和中东部大部将有4~6℃降温,
2025-01-06
-

守护百姓“看病钱” 国家医保局今年全面推进“码上”严监管
中新网1月2日电 据国家医保局微信公众号消息,2024年4月,国家医保局在全国范围开展药品追溯码采集应用试点工作。2024年11月初,针对某药品追溯码重复报销情况,在官方网站和微信公众号上对46家定点医药机构进行了公开问询,迈出了应用追溯码开展医保基金监管的第一步。2024年11月13日,12月6日,连续举办两场加强药品追溯码医保监管应用恳谈活动,邀请百余家医药企业参加,下发药品追溯码重复结算疑点
2025-01-03





